Scaling Orc8r Subscribers Codepath
With general patterns for economical set-interfaces.
- Status: Accepted
- Author: @hcgatewood
- Last Updated: 03/19
- Targeted Release: 1.5, 1.6
Overview
Summary
Orchestrator functionality currently drops dead around 18k subscribers, hindering our 1.5 release plans. Further, under the current architecture, our GA scalability targets would result in at least 850 terabytes sent over the network every month, necessitating a reexamining of our subscriber architecture. This document focuses on resolving scale issues for the subscriberdb codepath. We go on to describe a selection of tunable, increasingly effective mechanisms for improving the scalability of Magma’s set-interfaces.
We describe 4 objectives in this document
- ☠️ Resolve drop-dead scale cutoffs
- 💾 Reduce DB pressure at scale
- ☔️ Reduce network pressure at scale
- 💬 Simplify Orc8r-gateway subscriber interface
See the end of this document for resulting followup tasks.
tl;dr
- Resolve drop-dead scale cutoffs via service configs and pagination
- Reduce DB pressure 2000x, down to reasonable levels, via singleton cache service for southbound subscriber interface
- Reduce network pressure 500,000x in the expected case via flat subscriber digests and read-through cache gateway architecture, reducing 10-tenant network usage to expected under 2gb per month for GA scale targets
- Simplify Orc8r-gateway subscriber interface by moving from streamer pattern to unary RPC
Open questions
- Is 3 or 5 minutes a reasonable default interval for setting subscriber configs to the gateway? Current default is 1 minute, which we set in the streamer common code. Increasing would be an immediate win toward reducing DB and network pressure
- Are we okay with read-through cache model becoming the new default mode? Current model is Orc8r pushes all subscribers to all gateways, but one alternative is to model gateway as a read-through LRU cache of subscribers
- Immediate consequence: we architecturally lose the capacity to run in true headless mode. I.e., if an Orc8r goes down, gateways will only be able to serve subscribers currently cached at that gateway
- Upside: implemented well, this in tandem with flat subscriber digests would be a strong solution to our scalability issues while retaining set-interface benefits
- Timeline and prioritization
- Pagination and digests by release 1.5?
- Read-through cache mode by release 1.6?
Context
Overview
Magma’s chosen to propagate the “set-interface” pattern, where we set the full state on each update (snapshot-based), rather than sending a change list (diff-based). This pattern is desirable for stability and ease-of-implementation purposes, but it comes with the expected side effect of scalability issues on certain high-volume codepaths.
As a starting point, @karthiksubraveti is guiding the standing up of a repeatable scale-testing process, where we can get automated scalability metrics as part of a recurring CircleCI job. From there, this document describes additional patterns the dev team can use in the push to improve the scalability statistics.
The highest-volume codepaths are those directly or indirectly tied to the set of subscribers. Currently Orc8r supports ~18k subscribers, with drop-dead cutoffs. As a starting point, we need to remove the drop-dead cutoffs in favor of implementations that degrade gradually.
After solving the drop-dead cutoffs, Orc8r also needs to support true set-interfaces for codepaths that include order of 20k objects of non-trivial size. Based on some rough estimates, we can use 250 bytes as the baseline size for an average subscriber object. This results in needing to handle ~25mb of serialized objects on every get-all request. For reference, gRPC’s default incoming message size limit is 4mb.
To put it another way, consider a 10-network Orc8r deployment, where each network supports our GA target of 400 gateways per network and 20k subscribers per network. Under our current set-interface patterns, that Orc8r will be sending 1040020k*250 = 20gb of subscriber objects over the network every minute. Multiply that by 43800 minutes in a month, and that’s over 850 terabytes per month, just on subscriber objects.
Clearly this is an inadmissible number. This document describes patterns for moving this number to a manageable size while retaining the benefits of the set-interface. To start, consider each contributor to this final number
- 10 networks: reasonable target, no change
- 400 gateways: GA target, no change
- 20k subscribers: major improvement possible
- Total number of subscribers is GA target, no change
- Number of subscribers sent per-request, however, can be reduced by orders of magnitude. We present patterns for sending only updated subscribers, while maintaining set-interface principles.
- 250 bytes per subscriber: trivial improvement possible
- Average subscriber object could get down to maybe 150 bytes, a 40% improvement
- 43800 requests per month: minor improvement possible
- Instead of setting every minute, can default to every 3 or 5 minutes, an up to 5x improvement
From this listing, it’s clear the only non-trivial resolution to our GA scaling needs under a set-interface pattern must come with intelligently sending a trivial subset of subscribers on each request, rather than sending the full subscriber set.
This document focuses on the subscribers codepath for concreteness, but the described patterns should generalize to the subscriber-adjacent codepaths such as metrics ingestion and exporting.
Existing architecture
For an overview of Orc8r’s architecture, along with per-service functionality, see the Architecture Overview documentation.
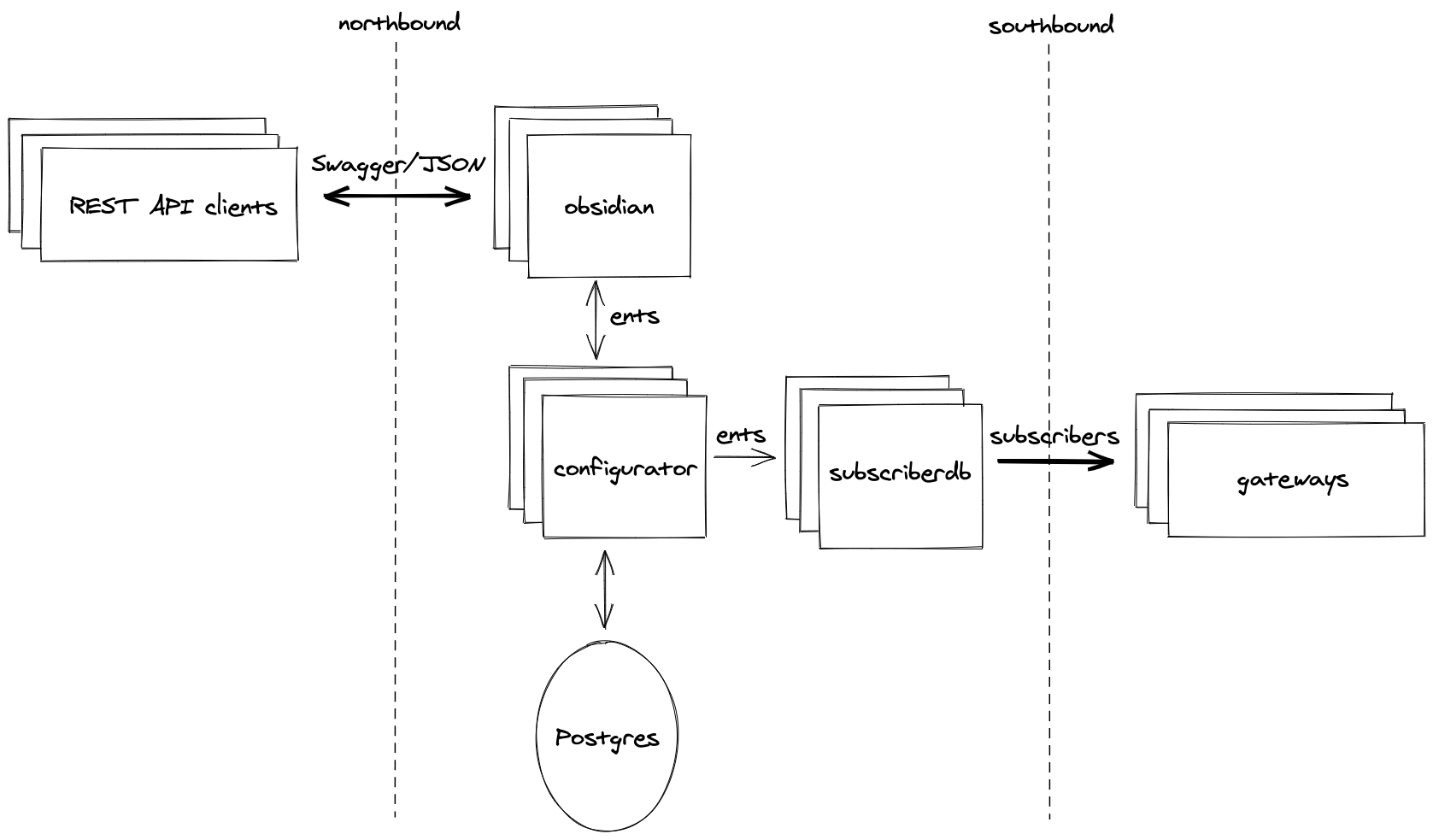
Subscriber objects
For context on the subscriber codepath: when we say “subscriber objects”, we refer to the SubscriberData protobuf. This proto contains subscriber-specific information, and each of these in a network is sent down to every gateway in the network, in-bulk, as the starting point for how the gateway should service a subscriber.
message SubscriberData {
// sid is the unique identifier for the subscriber.
SubscriberID sid = 1;
GSMSubscription gsm = 2;
LTESubscription lte = 3;
magma.orc8r.NetworkID network_id = 4;
SubscriberState state = 5;
string sub_profile = 6;
Non3GPPUserProfile non_3gpp = 7;
}
For context to the calculations in the previous section: a scale-testing issue raised by a partner indicated they hit gRPC max message size issues (4194304 bytes i.e. 4mb) at 18k subscribers => 4194304 / 18k = 233 bytes in basic scale testing => 250 bytes as baseline for average production subscriber object size.
Subscriber assumptions
The set of subscribers in a network is expected to follow a strongly read-dominated pattern. That is, updates to the set of subscribers are expected to be infrequent. To contextualize subsequent design recommendations, we’ll examine the following variously-representative operator behaviors, where for simplicity we only consider mutations, where a single mutation refers to a single subscriber object that needs to be re-sent down to gateways
- 🌟 1 write per day, 500 mutations each
- 1 write per hour, 50 mutations each
- 1 write per 10 minutes, 10 mutations each
- [non-goal] 1 write per 6 hours, 20k mutations each
- [non-goal] 1 write per minute, 100 mutations each
Consistency
Orc8r makes certain consistency guarantees which need to be upheld. Of specific concern are the consistency guarantees for configs along the northbound and southbound interfaces. The config codepath flows unidirectionally, from northbound (REST API), through the configurator service, and eventually out southbound (gateway gRPC). That is, northbound is many-readers-many-writers, while southbound is many-readers-zero-writers. To align on terminology, we’ll use terms from this Werner Vogels article on eventual consistency.
Existing guarantees
- Southbound: eventual consistency across the full set of subscriber objects — if a subscriber config is mutated, eventually all gateways will hold this updated set of all subscriber objects. Additional attributes of the eventual consistency include
- Monotonic read consistency: never read an older version of the full set of subscribers than one you have previously read
- Serializability: reading the full set of subscribers returns a value equal to the outcome of some previous write
- Northbound: strong consistency across the full set of subscriber objects — if a subscriber config is mutated, all subsequent readers will view the full set of subscriber objects as including the mutated config
Considered alternatives
Edge-triggered subscriber push. This document assumes we want to retain the set-interface pattern throughout Orc8r — for context, see level-triggered (state) vs. edge-triggered (events). A principal alternative to combat our scalability issues is to back away from this high bar and instead go with a hybrid approach, where e.g. we send state-based snapshots at infrequent intervals to correct any issues with the more-frequent event-based updates. However, we believe we can achieve reasonable scalability metrics without resorting to edge-triggered designs.
☠️ Objective 1: resolve drop-dead scale cutoffs
Overview
For both northbound and southbound interfaces (NMS and gateways, respectively), a get-all request reads all subscriber objects in a network, optionally manipulates them, and passes the result to the caller. This pattern drops dead in two immediate areas
- gRPC message size
- Problem
- If the full set of subscriber objects exceeds an arbitrary size limit (in bytes), the request will error out
- Can occur both at external service interfaces and internal service interfaces
- Operator recourse: none
- Partial resolution: make gRPC max message size a per-service Orc8r config
- Full resolution: paginate both REST API and gRPC endpoints on the “all subscribers” codepath. NMS and gateways will need to be updated to handle pagination. NMS will only use first page in the general case, while gateways will need to exhaustively consume all pages
- Problem
- DB query size
- Problem
- If the total number of subscriber objects exceeds ~18k, the DB query for “all subscribers” errors out at the DB side
- For MariaDB, the error is
Prepared statement contains too many placeholders - Multiple potential sources for this issue
- Can be triggered by an unfortunate implementation choice for how the ent library constructs its get-all queries. Affects subscriber state codepath
- Unclear/likely: may be triggered by certain non-scalable configurator queries. Affects subscriber config codepath
- Operator recourse: none
- Partial resolution: probably none
- Full resolution: determine source of issue and resolve
- State codepath: (a) coerce ent framework to make proper get-all requests, through upgrade or conniving, or (b) deprecate usage of ent library in favor of the base SQL blobstore implementation. I’m in favor of (b), since there’s no concrete reason to be using the ent library over our native SQL implementation
- Config codepath: determine if there is an issue on this codepath, then resolve in configurator implementation
- Problem
[immediate fix] Configurable max gRPC message size
As a starting point, we can’t catch every scaling issue during development. We need to provide operators with recourse for emergent scaling issues, whether they’re on the subscriber codepath or some other. The simplest solution is to provide every orc8r service a config value to set the max gRPC message size.
Implementation options: we can also consider having a single, cross-service config file, to avoid having to replicate (and remember to replicate for new services) the config value across service config files.
[medium-term solution] Pagination
Google provides a great description on how to paginate listable gRPC endpoints in their API Design Guide. We’ll reproduce their recommendations with Magma-specific considerations. This pattern is also flexible across gRPC and REST endpoints. Key tenets include
- Client should retain control over returned page size and rate of object reception
- Server can add configurable max page size
- If client sends page size of 0 (default), use server’s max page size. This should provide a measure of backwards-compatibility so outdated clients don’t fall down in scaled Orc8r deployments
- Pagination token (page token) should be opaque to the client
- If page token is empty string, return first page
For concreteness, we’ll examine the ListSubscribers gRPC endpoint. But the concepts are generalizable to the rest of the subscriber get-all codepath.
// subscriberdb
rpc ListSubscribers (...) returns (...) {}
message ListSubscribersRequest {
int32 page_size = 1;
string page_token = 2;
}
message ListSubscribersResponse {
repeated SubscriberID subscriber_ids = 1;
string next_page_token = 2;
}
// ListSubscribersPageToken is serialized then base64-encoded to serve as the
// opaque page token.
message ListSubscribersPageToken {
// last_included_subscriber_imsi is the last IMSI included in the previous page.
string last_included_subscriber_imsi = 1;
}
The configurator service stores entities with primary key (network_id, type, key). All requests are under a particular network ID, all subscribers have the same type, and subscriber IMSI is the key. This means a list of subscribers can be ordered on their primary key by their IMSI.
This allows us to use the fantastically scalable seek method for paginating DB requests. For example,
SELECT * FROM cfg_entities
WHERE
network_id = 'REQUESTED_NETWORK_ID' AND
type = 'subscriber' AND
key > 'PREVIOUS_IMSI_FROM_PAGE_TOKEN'
ORDER BY key DESC
LIMIT 100 /* requested page size */
;
For configurator-specific implementation, we can use EntityLoadCriteria to pass in page token and page size, and EntityLoadResult to return next page token.
Specifically for the subscriber codepaths, we need to
- Augment configurator to support pagination (subscriber config codepath), with propagation through northbound and southbound interfaces
- Augment state service to support pagination (subscriber state codepath), with propagation through northbound and southbound interfaces
Change to consistency guarantees. Under a paginated subscriber polling model, the full set of subscribers can be updated concurrently with an iterative request for the full set of subscriber pages. This slightly alters our consistency guarantees, but we should still have sufficiently-strong guarantees under the paging pattern. We note the difference between consistency on the “full set of subscribers” vs. consistency for “any particular subscriber.”
- Southbound: eventual consistency across the set of subscribers
- Monotonic read consistency: never read an older version of
the full set ofindividual subscribers than one you have previously read Serializability: a gateway can read a set of subscribers that never existed as the outcome from a previous write. However, this is admissible because (a) individual subscriber configs are updated atomically and (b) the full set of subscribers is still eventually consistent
- Monotonic read consistency: never read an older version of
- Northbound: strong consistency across
the full set ofindividual subscriber objects. As above, we lose the serializability guarantee for the full set of subscriber objects. However, we can still guarantee strong consistency on a per-object basis, meaning read-your-writes, monotonic read, and monotonic write consistency all apply on a per-subscriber basis
For both northbound and southbound interfaces, this change from “full set of subscribers” guarantees to “any particular subscriber” should not cause correctness issues, as a coherent view of the network-wide set of subscribers is not required for correct behavior — just coherence on a per-subscriber basis. That is, we only update subscribers on a per-subscriber basis, and never in-bulk — i.e., we update the single-subscriber object rather than the full-set-of-subscribers object. So reading an incoherent view of the full set of subscribers won’t cause any additional correctness issues because we don’t provide a way to write that full set of subscribers atomically.
[considered alternative] Server-side streaming
gRPC also supports streaming constructs, where server-side streaming is an attractive option for this use-case. However, we view server-side streaming as inferior to pagination due to the following issues
- DBs don’t easily support streaming responses
- Easy implementation: paginate requests to DB then stream response to gRPC client
- Harder implementation: DB-specific support for streaming responses. Breaks our usage of squirrel/sqorc to implicitly support both Postgres and Maria. Unclear if this is a common pattern, likely hidden gotchas
- Server-side streaming doesn’t play well with northbound (REST) endpoints
- Obsidian handlers have to be paginated, so they would need to deal with the complexity of converting a subscriber stream from subscriberdb into a paginated API response
- Bad experiences with gRPC streaming
- SyncRPC uses gRPC streaming by necessity, and the additional complexity involved with managing gRPC streams has contributed to our SyncRPC troubles
- More difficult to load-balance gRPC streams than unary endpoints
Since the subscriber get-all codepath is easier to implement via pagination at the DB side, and needs to support pagination on the northbound interface, we can avoid unnecessary complexity by making the entire codepath paginated rather than a mix of pagination and streaming.
Upshot
- Configurable max gRPC message sizes affords operator recourse to scale issues
- Paginating the get-all subscribers codepath resolves drop-dead scale cutoffs
💾 Objective 2: reduce DB pressure at scale
Overview
Scale tests have noted DB timeout issues for subscriber get-all requests, specifically for the configurator service. This is likely due to lock contention within the DB, as a get-all request is made 1 time per minute for each gateway in the network and 2 times per minute for each NMS instance open in a browser. For our GA scale targets of 400 gateways, this results in 4,032,000 DB get-all requests across a 7-day period. Caching is a straightforward solution here.
Side note: pagination through to the REST API should reduce the NMS-induced DB pressure, but this is a minority contributor in the expected case.
[immediate fix] Increase default subscriber streamer sync interval
Current default is 1 minute. Moving this to 3 or 5 minutes would give us immediate breathing room for dealing with DB pressure.
[immediate fix] Shorter DB timeouts
In the scale testing setup, experiment with adding more aggressive timeouts to all application DB requests — and this timeout should be shorter than the frequency with which the subscriber stream is updated. This may help prevent the DB from getting bogged down under excessive request weight, instead clearing outdated requests to ease the path toward non-degraded functionality.
Another consideration is relaxing transaction isolation levels. Unfortunately, configurator already has relaxed isolation levels — it doesn’t use serializable isolation except on table creation, and it uses Postgres-default Read Committed isolation for entity reads.
[medium-term solution] Singleton get-all caching service
Add a single-pod subscriber_cache service which makes the get-all DB request at configurable interval, e.g. every 30 seconds, generates the subscriber objects, and exposes them over a paginated gRPC endpoint. Subscriberdb can then forward subscriber get-all requests to subscriber_cache rather than calling to configurator then manually constructing the objects.
// subscriber_cache
rpc ListCachedSubscribers (...) returns (...) {}
message ListCachedSubscribersRequest {
// similar to ListSubscribersRequest
}
message ListCachedSubscribersResponse {
// similar to ListSubscribersResponse
}
We can get away with caching like this on the southbound interface because gateway subscriber information is only eventually consistent, and our implicit SLA is currently order of 60 seconds.
Note: for simplicity we describe this as a separate, singleton service. But it doesn’t actually need to be a separate service or singleton, and instead we could inject this functionality directly into the subscriberdb service, with some DB-based synchronization for determining the most-recent digest, to avoid churn caused by gateways alternating connections between subscriberdb pods with different cached views of the subscriber objects. However, a benefit of the singleton approach is it provides an easy way to get a globally-consistent view of the full set of subscribers, side-stepping inconsistent digest issues discussed in subsequent sections.
[considered alternative] Redis cache
This solution is not worth the complexity it would entail at this point, where we’re just trying to get to 50-100k subscribers per network with eventual consistency in replicating down the southbound interface. However, a Redis cache in front of the configurator data is a reasonable long-term option if the single-pod subscriber_cache service becomes a bottleneck due to increased scaling requirements or need for more granular, write-aware caching.
Scalability calculations
To contextualize the proposed changes in this section, consider the representative operator behaviors presented above, with a single-tenant Orc8r deployment with GA targets of 20k subscribers and 400 gateways over a 7-day period. We’ll assume the southbound cache refresh occurs every 5 minutes, which means
- Previous architecture causes (1440*7)(400) = 4,032,000 DB hits
- Proposed caching pattern would result in (1440*7/5)(1) = 2016 DB hits, a 2000x improvement
Upshot
- Increasing sync interval gives immediate breathing room
- Shorter DB timeouts help prevent transaction backlog
- Southbound subscriber caching reduces DB pressure
- 2000x reduction in DB hits under proposed changes
☔️ Objective 3: reduce network pressure at scale
Overview
We want to retain the set-interface aspect of the southbound subscriber codepath, and the easiest way to handle this is already used within Orc8r — protobuf digests. Go’s proto third-party package supports deterministic protobuf serialization. We can leverage this to generate digests of the subscriber objects, allowing a short-circuit of the full network transmission in the common case.
An additional, synergistic option is modeling gateways as read-through subscriber caches. Then, instead of the Orc8r sending the full set of subscribers to every gateway, each gateway instead receives only a requested subset of subscribers, updated on-demand. This would alter some existing Magma affordances, specifically around “it just works” headless gateway operation, but the scalability wins may make for a worthwhile trade-off.
[medium-term solution] Flat digest of all subscribers
Similar to the way mconfig requests take an extraArgs *any.Any argument from the client (which is then coerced to a digest), endpoints on the subscriber get-all codepath can take a previous_digest string parameter. If the client’s digest matches the server’s digest, a no_updates boolean can short-circuit the request.
rpc ListSubscribers (...) returns (...) {}
message ListSubscribersRequest {
// ...
// previous_digest is the digest received from the most-recent request to
// ListSubscribers.
string previous_digest = 4;
}
message ListSubscribersResponse {
// ...
// digest is the server-defined, deterministic digest of the full set of
// returned subscriber objects.
string digest = 3;
// no_updates is true if client's existing subscribers match those on the
// server.
bool no_updates = 4;
}
For performance purposes, the subscriber_cache service can compute and expose the digest each time it updates its cache
// subscriber_cache
message ListCachedSubscribersResponse {
// ...
// digest is the server-defined, deterministic digest of the full set of
// returned subscriber objects.
string digest = 3;
}
Some followup notes
- Can include support for computing digests incrementally and/or concurrently
- Since we’re transitioning to pagination of subscriber get-all endpoints, we’ll no longer provide a mechanism to retrieve a serializable view of the full set of subscribers. This will restrict our capacity to generate effective digests. However, consider the following affordances
- Since our expected operator patterns are exceedingly read-heavy (i.e. writes expected order of once per day in common case), it’s reasonable to assume that, the vast majority of the time, a reader’s view of the full set of subscribers will happen to be a serializable view
- The above-mentioned singleton
subscriber_cacheservice resolves this issue in practice, providing, if not serializable, at least a globally-consistent view - The below-mentioned tree-based digest pattern is resilient against globally-inconsistent views of the full set of subscribers
- Because protobufs explicitly do not support canonical encodings, all digests must be generated at the Orc8r
- We’ve had some unconfirmed reports of mildly unstable (non-deterministic) protobuf encodings. This would remove a large chunk of the performance wins, so is worth validating before fully committing to this pattern. Some workaround resolutions, if necessary, in increasing order of difficulty to implement
- If the encoding is only mildly unstable (and with uniform distribution), the
subscriber_cacheservice can compute the digest multiple times per cache refresh, storing the set of digests rather than just the single digest. Clients can still send a single digest, and servers check that digest against the list. This is hacky but potentially feasible - Upstream, find, or fork the proto library to resolve the source of the non-determinism
- Use the entity versioning alternative considered below — with read-through cache mode this could be sufficient
- Abandon true set-interface architecture in favor of hybrid — send updates as they occur, with snapshot checkins at much longer intervals
- Other options ?
- If the encoding is only mildly unstable (and with uniform distribution), the
[long-term solution] Tree-based digest: Merkle radix tree
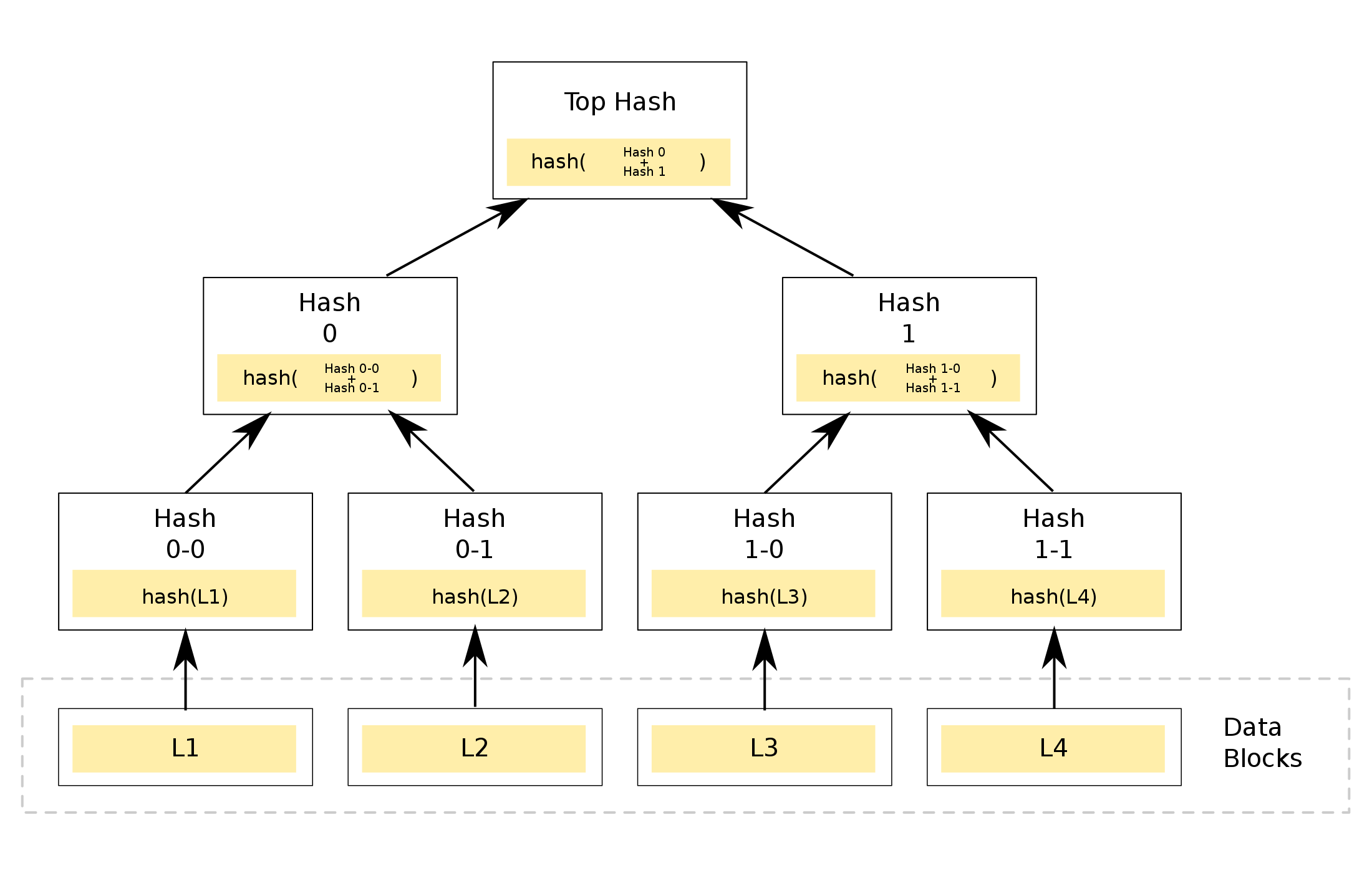
If the assumption of minimal subscriber updates is violated, or we scale past viability of the flat digest pattern, we can gracefully transition to a tree-based digest pattern. This will allow arbitrarily-high resolution understandings of which subscriber objects need to be sent over the network. And since this pattern is resilient to lost updates, we retain the benefits of the set-interface pattern.
Context: Merkle tree. Merkle trees allow tree-based understanding of which data block (in our case, subscriber object) has mutated. See this Merkle tree visualization to get an intuitive understanding. With two Merkle trees, you can start with the root nodes, compare, then recurse to each child until you find one of the following
- a node whose subtree contains all changes — i.e. the lowest node with more than 1 mutated child hash
- a set of nodes whose subtrees collectively contain all changes — with tunable precision for number of nodes
- the exact set of mutated data blocks (subscriber objects)
Context: Radix tree. Prefix trees support stable, deterministic arrangement of objects based on string keys. In their compressed form they’re called radix trees, which is what we’ll want to use. See this radix tree visualization to get an intuitive understanding.
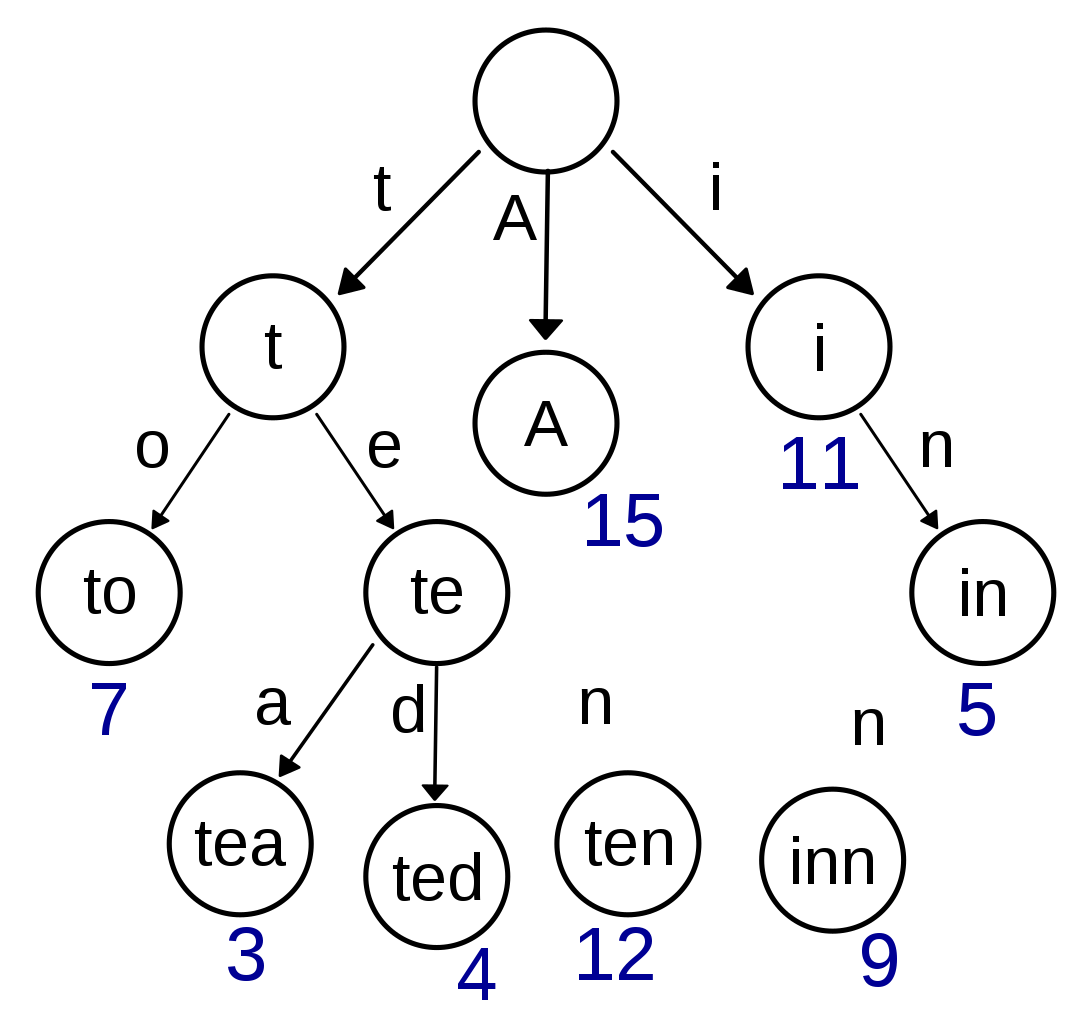
Solution: Merkle radix trees. Combining Merkle and radix trees allows us to organize the full set of subscribers into a stable, IMSI-keyed tree (radix tree), then recursively generate digests for each node up the tree (Merkle tree). This unlocks arbitrarily fine-grained control over how many subscriber objects must be sent, even under high subscriber write volume. Note that, per our Swagger spec, an IMSI can contain between 10 and 15 digits, inclusive. This results in a maximum tree depth of 15 and maximum branching factor of 10, and due to the nature of radix trees the full tree size will only be a function of the total number of subscribers.
- Client sends top n levels of tree. Server can send subset of full subscribers, even when the full set has changed. For a single subscriber change, and assuming uniformly-distributed IMSI strings (or comparable change in choosing how much of the tree to send), every additional level reduces the number of subscribers to be sent by 10x. If we ever get to implementing this, we would want to get some hard statistics to support this calculation.
- Client sends full tree. Tree size is tunable based on chosen digest algorithm, but e.g. for MD5, which has a 16-byte digest, a tree for 100k subscribers would result in a tree size of about 3mb. However, sending the full tree in the request would allow the response to contain exactly the set of differing subscribers.
- 🌟 Multi-round client-server communication. Client and server communicate back-and-forth, for number of rounds up to depth of the tree (max 15 for our IMSI constraints). Network bandwidth is minimal and strictly related to the number of mutated subscribers. While this variant would require up to 15 round-trips, only exactly the mutated subscribers would be sent on the final trip, and with trivial cost to network bandwidth.
Some followup notes
- Based on scalability calculations below, the full multi-round pattern is the only variant that resolves scale issues
- Side note on why we can’t use just a Merkle tree: we don’t have a good way to get the subscribers into a stable arrangement. We could sort them into a flat list, but removing the first subscriber would shift every hash in the tree. The radix tree solves this problem.
- As a lower-priority concern: we should probably still perform an infrequent snapshot-based re-sync to handle the corner case of incidental hash collisions. Depending on the probability of such collisions, we could make this full re-sync arbitrarily infrequent.
[long-term solution] Configurable gateway subscriber views
Current architecture has a single, global view of the full set of subscribers, and each gateway receives a full copy of that global view. However, we don’t necessarily need to have a single view — instead, we can have the Orc8r view (global, all subscribers) and a new, per-gateway view (non-strict subset). Supporting gateway-wise views unlocks sending only a subset of subscribers to a particular gateway, independent of whether we include the digest pattern, while retaining set-interface benefits.
From an implementation perspective, we can support a per-network, REST-API-configurable “gateway view mode”, with the following 3 modes, where we can default to the read-through cache mode.
Identical, global view. This is the current pattern. Every gateway receives all subscribers, in an eventually-consistent manner. Supports headless gateways and mobility across headless gateways.
Static mapping. Operators manually map subscribers to gateways. Useful for restricting subscribers to a particular CPE, for example.
Gateway as read-through cache. Gateways only pull subscribers on-demand. Supports headless gateways but not mobility across headless gateways.
- Even in our GA-target deployments with 20k subscribers per network, each gateway will serve no more than 1k subscribers at a time, with the expected number much closer to the 50-500 range — that’s 2-3 orders of magnitude fewer subscribers per gateway
- Instead of proactively sending all subscribers in a network down to a particular gateway, the gateway can instead dynamically request particular subscribers in an on-demand manner — i.e., only when necessary, as deemed by the gateway. We can then consider a gateway to be “following” a subset of the network’s subscribers, and receive poll-based updates on only that subset of subscribers at every update interval. Note that the gateway would be responsible for updating its “follow” list of subscribers and sending it in requests for subscriber objects, allowing Orc8r to support these gateway views in a stateless manner
- An immediate consideration for the read-through cache pattern is “unfollowing” a subscriber the gateway no longer needs, to avoid application-level Redis memory leaks. For this, we can turn to a potential implementation choice. Consider a small service or bit of library code used as the entry point for reading a subscriber object from Redis at the gateway. If the object returns missing, the module handles (a) proactively reaching out to Orc8r for the subscriber object and (b) following that subscriber to receive future updates. Since this is a read-through cache, we can use a simple LRU caching policy, and/or just fully clear the cache (and subscription list) at infrequent interval
- Side note: while we can start by setting cache size to a sensible default, it probably makes sense to give Orc8r control over this, to empower operators to e.g. increase cache size for gateways under heavy load
- Once a gateway is following a set of subscribers, the gateway can poll Orc8r for just the subset of subscriber objects it’s currently following. Each gateway manages its own follow-list, and sends it its subscriber polling request, affording Orc8r a stateless implementation of per-gateway subscriber views
[considered alternative] Configurator entity-type versioning
One medium-term alternative to digest-based caching is to outfit configurator with an atomic counter, per entity type, which is incremented on every mutation to an entity of that type. This can be exposed to the read endpoints, allowing readers to determine with low resolution whether there has been a change to any entity of the chosen type. Instead of storing and sending digests, gateways can include relevant version numbers as a drop-in replacement — that is, since the digest has no semantic meaning to clients, we can literally place the version number into the digest fields mentioned previously.
One consideration for this solution is that subscriberdb pulls multiple entity types when it constructs the subscriber protos. The version number actually exposed to clients would need to be a function of the full set of version numbers consumed from configurator by subscriberdb.
We slightly prefer the digest-based pattern, but are open to feedback. Downsides to the versioning solution include
- Not progressively scalable — on any change, no matter how small, Orc8r must send all subscribers in the network to every gateway in the network
- Increases configurator complexity, where configurator is already complex and the largest Orc8r service
- As mentioned, subscriberdb would need to consider versions of multiple types, since e.g. APN configuration is pulled into the subscriber objects
[considered alternative] 3GPP tracking areas
Rather than sending all subscribers in a network to all gateways, we can use the 3GPP concept of tracking areas to map which subscribers should be sent to which gateways. However, this approach is insufficient as we can’t make strong assumptions on how operators set and manage their tracking areas, and there’s no guarantee that a UE won’t travel to a gateway outside their tracking area.
Resilience considerations
Non-serializable subscribers view. We expect quite infrequent writes to the set of subscriber configs, meaning most “get all subscribers” requests will happen to retrieve a serializable view of the subscribers. Additionally, tree-based digest patterns allow sending exactly the set of subscribers that constitute the delta between Orc8r and gateway. So even though a subscriberdb pod’s non-serializable view of the full set of subscribers may occasionally result in slightly mismatched digest trees, the resulting network pressure will be minimal since only the delta between the two digest trees needs to be transmitted on the subsequent poll. Finally, using the previously-described subscriber_cache pattern as a singleton service largely resolves this issue by affording a globally-consistent, if still non-serializable, subscriber view. With this effectively globally-consistent view, only a trivial subset of all requests will see an inconsistent view of the full set of subscribers, removing the potential negative of often-mismatched digests.
Software bugs. Digest-based patterns rely on gateways appropriately storing and including digests in their requests to the southbound subscribers endpoint. Consider two scenarios.
Scenario A. If a misbehaving gateway polls the endpoint in rapid succession, with garbage digests, the Orc8r could easily get DoS’d and/or accrue excessive opex costs. Safety latches will need to be built into the system to impede such misbehaving gateways.
Scenario B. We can also imagine a partial bug in how an Orc8r calculates digests. This would cause similar outcomes, where the Orc8r is attempting to pump exact copies of its subscriber objects out to most or all polling gateways, driving up opex costs and leading to potential self-DoS issues.
In both scenarios, network pressure improvements are either partially lost (scenario A) or up to completely lost (scenario B). The principal prospects for ameliorating these failure modes are
- resorting to edge-triggered architecture (considered alternative, not chosen for now)
- gateways subscribe to minor subset of full subscriber set (read-through cache)
The latter solution doesn’t resolve scenario A, but it does restrict the scope of opex and self-DoS issues in scenario B.
Scalability calculations
To contextualize the proposed changes in this section, consider the representative operator behaviors presented above, with a single-tenant Orc8r deployment with GA targets of 20k subscribers and 400 gateways over a 7-day period. Under this context, the existing architecture results in (1440*7)(400)(20000) = 80 billion subscriber objects sent over the network over a 7-day period — that’s 20 terabytes. For the below calculations, we’ll assume the new default southbound poll interval is 5 minutes, and that each gateway serves a uniform share of the subscribers (i.e. 50 subscribers at each gateway) with no subscriber mobility
- 🌟 1 write per day, 500 mutations each
- Read-through cache: (1440/57)(400)(20000/400250b) = 10gb
- Flat: (17)(400)(20000250b) = 15gb
- Flat + read-through cache: (17)(400)(20000/400250b) = 40mb
Full tree: (1440/57)(400)(3mb) overhead + (17)(400)(500*250b) from subs = 2tb- (Multi-round) tree: trivial overhead + (17)(400)(500250b) from subs = 350mb
- (Multi-round) tree + read-through cache: trivial overhead + (17)(400)(500/400250b) from subs = 1mb
- 1 write per hour, 50 mutations each
- Read-through cache: (1440/57)(400)(20000/400250b) = 10gb
- Flat: (247)(400)(20000250b) = 330gb
- Flat + read-through cache: (247)(400)(20000/400250b) = 850mb
- Tree: trivial overhead + (247)(400)(50250b) from subs = 850mb
- Tree + read-through cache: trivial overhead + (247)(400)(50/400250b) from subs = 2mb
- 1 write per 10 minutes, 10 mutations each
- Read-through cache: (1440/57)(400)(20000/400250b) = 10gb
- Flat: (1440/107)(400)(20000250b) = 2tb
- Flat + read-through cache: (1440/107)(400)(20000/400250b) = 5gb
- Tree: trivial overhead + (1440/107)(400)(10250b) from subs = 1gb
- Tree + read-through cache: trivial overhead + (1440/107)(400)(10/400250b) from subs = 3mb
- [non-goal] 1 write per 6 hours, 20k mutations each
- Read-through cache: (1440/57)(400)(20000/400250b) = 10gb
- Flat: (47)(400)(20000250b) = 60gb
- Flat + read-through cache: (47)(400)(20000/400250b) = 150mb
- Tree: trivial overhead + (47)(400)(20000250b) from subs = 50gb
- Tree + read-through cache: trivial overhead + (47)(400)(20000/400250b) from subs = 150mb
- [non-goal] 1 write per minute, 100 mutations each
- Read-through cache: (1440/57)(400)(20000/400250b) = 10gb
- Flat: (1440/57)(400)(20000250b) = 4tb
- Flat + read-through cache: (1440/57)(400)(20000/400250b) = 10gb
- Tree: trivial overhead + (1440/57)(400)(500250b) from subs = 100gb
- Tree + read-through cache: trivial overhead + (1440/57)(400)(500/400250b) from subs = 250mb
Note that for target use-cases, the proposed multi-round tree pattern in conjunction with read-through cache architecture invariably keeps 7-day network usage under 250mb for a single-tenant Orc8r at our GA scale targets, an 80,000x improvement even under worst-case assumptions.
Upshot
- [short-term] Flat digest reduces GA 7-day total network usage under 15gb for common case
- [medium-term] Flat digest with read-through cache reduces GA 7-day total network usage under 1gb for most expected cases
- [long-term] If read-through cache mode proves an unworkable solution, or write-heavy subscriber update patterns become the norm: tree-based digest with read-through cache reduces GA 7-day total network usage under 250mb for all considered cases
💬 Objective 4: simplify Orc8r-gateway interface
Overview
Due to the immediate need for pagination of the get-all subscriber endpoints, gateways need to be updated to gracefully handle these updated endpoints by greedily consuming all pages in an update. Additionally, the southbound subscriber interface will need to provide affordances to support the read-through cache functionality.
We currently use the streamer pattern to send all subscribers as a data update to the subscriberdb stream. We have generic code on the gateway that handles receiving updates from a stream and acting based on the received updates. This entire codepath (Orc8r and gateway) would need an update to handle exhaustively reading from the stream, since currently we assume all data updates are contained in a single update batch. This would cause collateral risk to every streaming functionality in the Magma platform: mconfigs, subscribers, policies, rating groups, etc., most of which do not and likely will not need support for multi-page reads.
[short-term] Migrate to unary RPC
Instead, the preferred option is to begin the already-initiated process of moving away from the streamer pattern. It’s a legacy pattern from when we considered support for pushing event-triggered changes down to the gateways. However, with the refocusing toward set-interfaces, and the fact that we have zero Orc8r support whatsoever for event-based stream triggers (streams are just updated on a timed loop), the streamer pattern loses out on its main positives. Instead, we’re left with an unnecessary layer of indirection between Orc8r and gateways, with the added complexity of having to deal with gRPC streams for no specific benefit.
As an aside, the current streamer pattern handling at both Orc8r and gateways doesn’t actually make use of the server-side streaming functionality built in to the streamer pattern — we only ever make single requests then close the steam. So we’re effectively doing “unary” gRPC calls with extra cruft.
That to say, rather than retrofitting the streamer pattern, we can instead fully move to a pull-based model for polling the subscriber codepath. Benefits of this refactoring approach include
- Backwards compatibility — we can leave the existing subscriber streamer codepath intact and untouched for the next release, with the note that it will be insufficient for high-scale deployments
- Forward compatibility — if we want to experiment with transitioning to tree-based digests in the future, having a single-purpose standalone unary RPC allows zero-collateral changes to the subscriber code path
- Reduce collateral risk — no hidden risks in a major change to the streamer pattern accidentally breaking major components of the Orc8r-gateway interface
- Simpler end-implementation — streamer’s layer of indirection results in unnecessary, repetitive code at both Orc8r and gateway. Exposing the subscriberdb stream as a direct endpoint allows a simpler implementation, where gateways just make iterative unary requests until the returned page token is empty
Additional considerations
Orc8r-controlled poll frequency. We can give Orc8r control over the update frequency by adding an mconfig field to relevant services to set the gateway’s polling frequency, with chosen default value. Then each mconfig update (1 minute) is an opportunity for an Orc8r to tune a gateway’s subscriber update frequency.
Upshot
- Migrate southbound subscribers endpoint to pull-based unary RPC
- Give Orc8r control over gateway polling frequency
Conclusion: followup tasks
v1.5
- [P1][XXS] 🔥 Implement and document new default subscriber polling frequency of 3 minutes
- [P1][XXS] 🔥 Give all orc8r services a configurable max gRPC message size
- [P1][M] Paginate all endpoints along the “get all subscribers” config codepath
- Update Orc8r codepath (configurator), through to northbound and southbound interfaces
- Update gateway consumption: either retrofit streamer code to handle pagination, or migrate to unary RPC
- Updated NMS to handle paginated Orc8r REST API
- Side note: NMS creates a gateway→subscriber map based on getting all subscribers and all gateways. Move this functionality to an Orc8r
/lte/networks/{network_id}/gateways/{gateway_id}/subscribersendpoint, fully removing the need for NMS to make get-all subscriber requests. May need to use state indexers pattern to implement this endpoint
- Side note: NMS creates a gateway→subscriber map based on getting all subscribers and all gateways. Move this functionality to an Orc8r
- [P1][S] Identify source of “DB statement too large” error and resolve
- If from ent.go (state codepath): resolve ent.go’s poor get-all query construction or remove it in favor of SQL blobstore implementation. Latter option will likely require a migration
- If from configurator (config codepath): resolve poorly-constructed query
- [P1][S] Add flat digests to get-all subscriber codepath
- Validate determinism of protobuf encodings across 10-20k subscriber protos
- [P2][XXS] Document Orc8r’s consistency guarantees in Docusaurus architecture section
- [P2][XXS] Shorten application DB timeouts to less than the subscriberdb stream update frequency
- [P2][M] Paginate all endpoints along the (subscriber) state codepath
- Update Orc8r codepath (state service), through to northbound and southbound interfaces
- Update gateway state reporting
v1.6
- [P1][S] Add get-all subscriber caching functionality as separate singleton service
- If necessary — v1.5 work may uncover that this cache is unnecessary
- [P2][L] Add support for gateway subscriber views, with REST API-configurable modes of populating
- If necessary — there’s imperfect alignment on whether this is the best path forward, so we’ll revisit this after the v1.5 work is complete
- Modes
- Read-through cache (new default)
- Global/identical (current)
- [P2][XS] Give Orc8r per-gateway control over subscriber poll interval and read-through cache size
- Add relevant field to subscriberdb’s mconfig, allowing control from Orc8r REST API
Non-goals
- Revamp Orc8r’s security considerations of subscriber data
- Handled outside the scope of this document
- Remove APN configuration information from streamed subscriber objects. While this may reduce average subscriber object size, this size is only a minor contributor to current scale challenges