Scaled Prometheus Pipeline
Author: Scott Smith
Feature Owner: Scott Smith
Requires Feedback From: Jacky Tian
Details:
- I use the term pushgateway to reference prometheus-edge-hub
- "Prod" and "Staging" refer to FB-hosted deployments of Orchestrator which are currently our largest deployments and our source of performance data.
Goal: Improve metrics query speed on large deployments
The current magma metrics deployment involves only a single Prometheus server, with no option for scaling. While this is sufficient for writing, the query side is already seeing some performance issues. For example, loading grafana on prod takes more than 5 seconds. This is due to the queries grafana has to make to populate the list of networkIDs and gatewayIDs being slow. While the production deployment is currently the largest that exists, we don’t want to have partners run into serious metrics performance issues as they build large networks. We need to scale prometheus to improve query performance.
Data
Prometheus
On prod we currently have ~347 active gateways, and ~105k metric series
Query times for PromQL query count({__name__=~".+"})
| Time Range | Query Time |
|---|---|
| 1m | 3141ms |
| 5m | 7801ms |
| 15m | 6966ms |
| 30m | 6025ms |
| 1h | 6153ms |
| 2h | 8186ms |
| 6h | 11957ms |
| 12h | 17983ms |
| 1d | TIMEOUT |
Even the smallest query range takes over 3 seconds, and over any significant period of time the query times out. This is definitely not “snappy” and will not provide a good user experience with a large network. This data fits in with prometheus recommendations that queries should not have more than ~100k series.
Grafana
The main problem with long query times is less responsive dashboards.
Time to load grafana dashboard on prod NMS: **>15s **from click until all graphs are populated. Most of this time is spent looking at all series in order to determine the set of available networkIDs and gatewayIDs.
Proposed Solution
Thanos
Thanos is a very popular project which allows for easy and customizable scaling of prometheus monitoring pipelines. From the start, I believe this will be the easiest and most powerful solution to the problem. Thanos consists of several components, all of which can be used independently. The most relevant to us is the Querier which allows for the querying of data across multiple prometheus servers. A simple architecture diagram from Thanos shows how this works in a typical deployment:
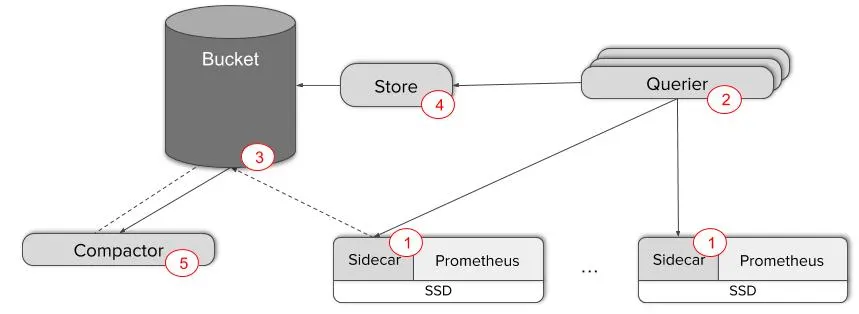 Here we see multiple prometheus servers with the Thanos
Here we see multiple prometheus servers with the Thanos sidecar attached. This allows for the rest of the thanos components to work together. Then, the Querier components are able to accept PromQL queries and retrieve data from any set of the prometheus servers.
With this setup, we only need to deploy the Thanos sidecar and multiple Querier components, along with Object storage to achieve faster queries.
Deploying Thanos in Orchestrator
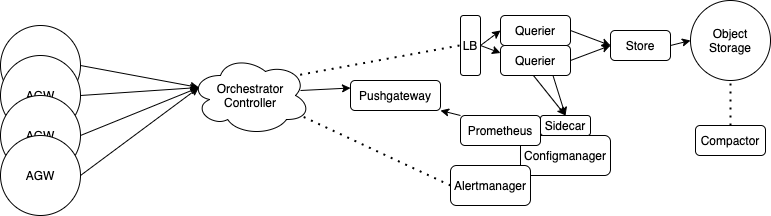
Our solution will consist of:
- A single prometheus server with an attached Thanos sidecar
- Multiple Thanos querier components behind a load balancer
- Object storage to store metrics that are older than a couple of hours to remove query responsibility from the prometheus server
- A Thanos compactor component to periodically compact the metrics in object storage to reduce storage requirements.
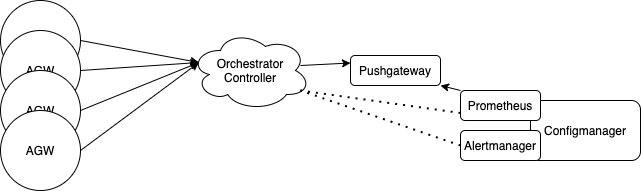
In this solution, the flow of metrics is not changed until it gets to the prometheus server. Metrics still begin on the AGWs and are sent to the controller where they are processed in the metricsd service. metricsd then pushes the metrics to a pushgateway, where they are scraped by the prometheus server. Now instead of ending here, they are sent to object storage (described below) and remain for long term storage.
Current metrics pipeline diagram:
Proposed pipeline:
Improving query times with Object Storage
All metrics go through the controller (which is already scalable and placed behind a load balancer), where they are pushed to the prometheus-edge-hub (or pushgateway). The single prometheus server then scrapes from this pushgateway.
All metrics are stored for 30 days in the Prometheus TSDB storage. This means that all queries have to go through the prometheus server itself, which is the main cause of slow queries.
Object storage will allow us to only store a few hours of metrics on the server itself (potentially keeping everything in-memory) and then exporting older metrics to object storage elsewhere. For example on an AWS deployment metrics would be stored in S3.
Options for Object Storage
- Deployed on AWS: S3
- Deployed with openstack: Openstack Swift
- Neither: Use prometheus server and forgo object storage
Query-side Implementation
We will deploy multiple Querier components behind a load balancer which are configured to talk to both the prometheus server and the Object storage. This will distribute the compute and I/O load away from the prometheus server to the stateless querier components which can be trivially scaled horizontally to handle increased query loads. Currently, the orchestrator API reaches out directly to the Prometheus server to query metrics data, but now the API will point to the Thanos querier components. Nothing else will change in terms of the API.
Configuration
We should make this as easy to configure as possible. Some goals include:
Make this entire setup optional. The single prometheus server works well for small to medium deployments.
Configuring thanos to run in Orc8r should require no more than a few values in the helm chart. (e.g.
create_thanosandprometheus_servers_count)Since we are moving the prometheus-configmanager to act on the Thanos Ruler component, we can manage prometheus server configuration with Kubernetes and ConfigMaps. This will be used to correctly set scrape targets for the servers with respect to the multiple pushgateways.
Improving prometheus-edge-hub performance
With the goal of handling 10 million datapoints per minute, the prometheus-edge-hub will probably need some improvements to handle that load. First we'll do benchmark tests on specific AWS hardware options. Then, profile the code to find the bottlenecks and improve them. It's not clear what exactly needs to be done, but I'm confident we can find significant improvements as this component hasn't gone through much optimization yet.
In the end if we can't get enough performance out of a single edge-hub, we will have to investigate scaling this horizontally.
Development Plan
| Step | Est. Time |
|---|---|
| Deploy Thanos locally and experiment with loads to validate query time improvements | 2 wk |
| Deploy Thanos with a single prometheus server in Orchestrator to test that the Querier and sidecar don’t cause any unexpected side effects. | 1 wk |
| Add Object storage | 2 wk |
| Investigate performance improvements in prometheus-edge-hub | 2 wk |
| Configure helm chart | 2 wk |
| Deploy to staging/prod | 1 wk |